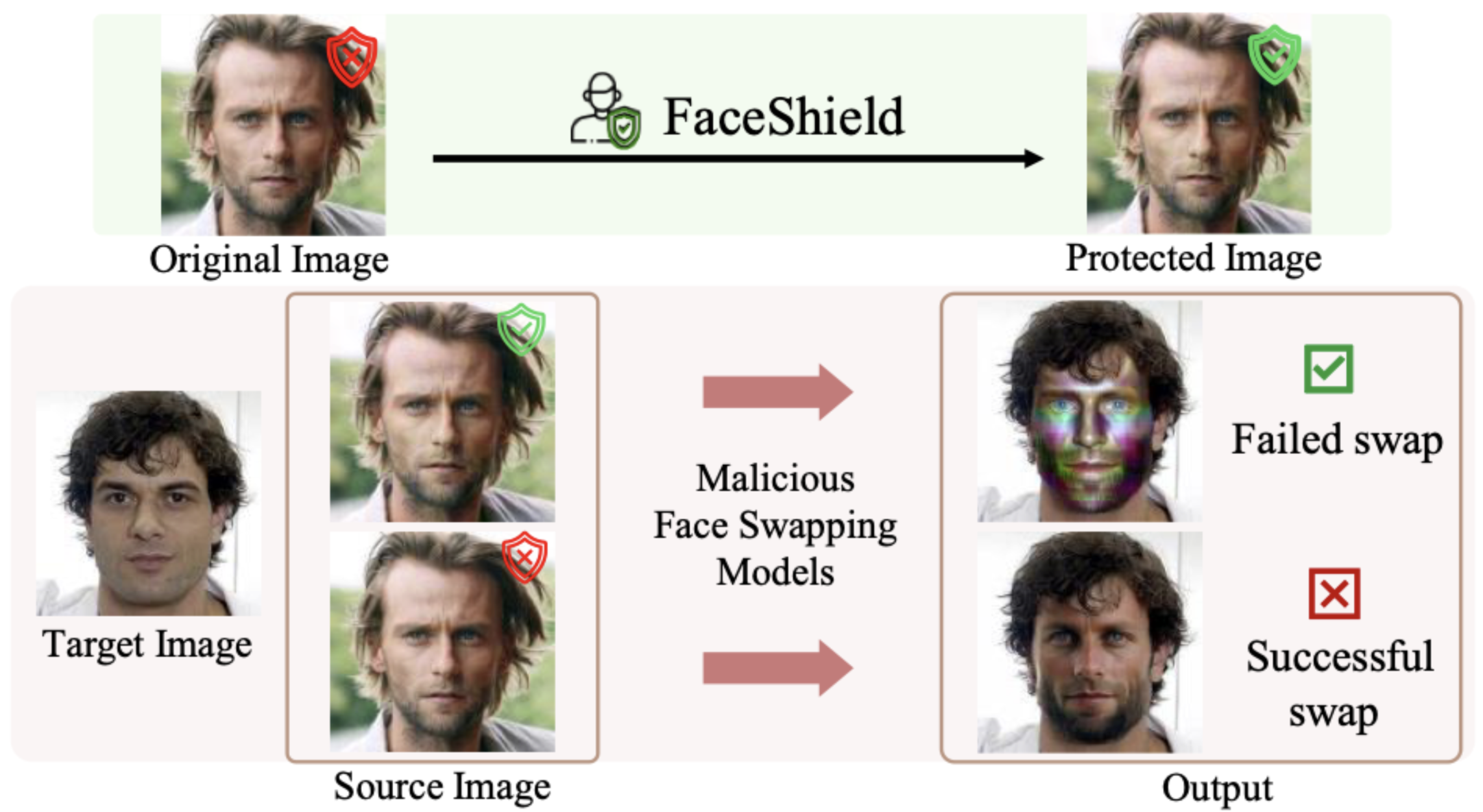
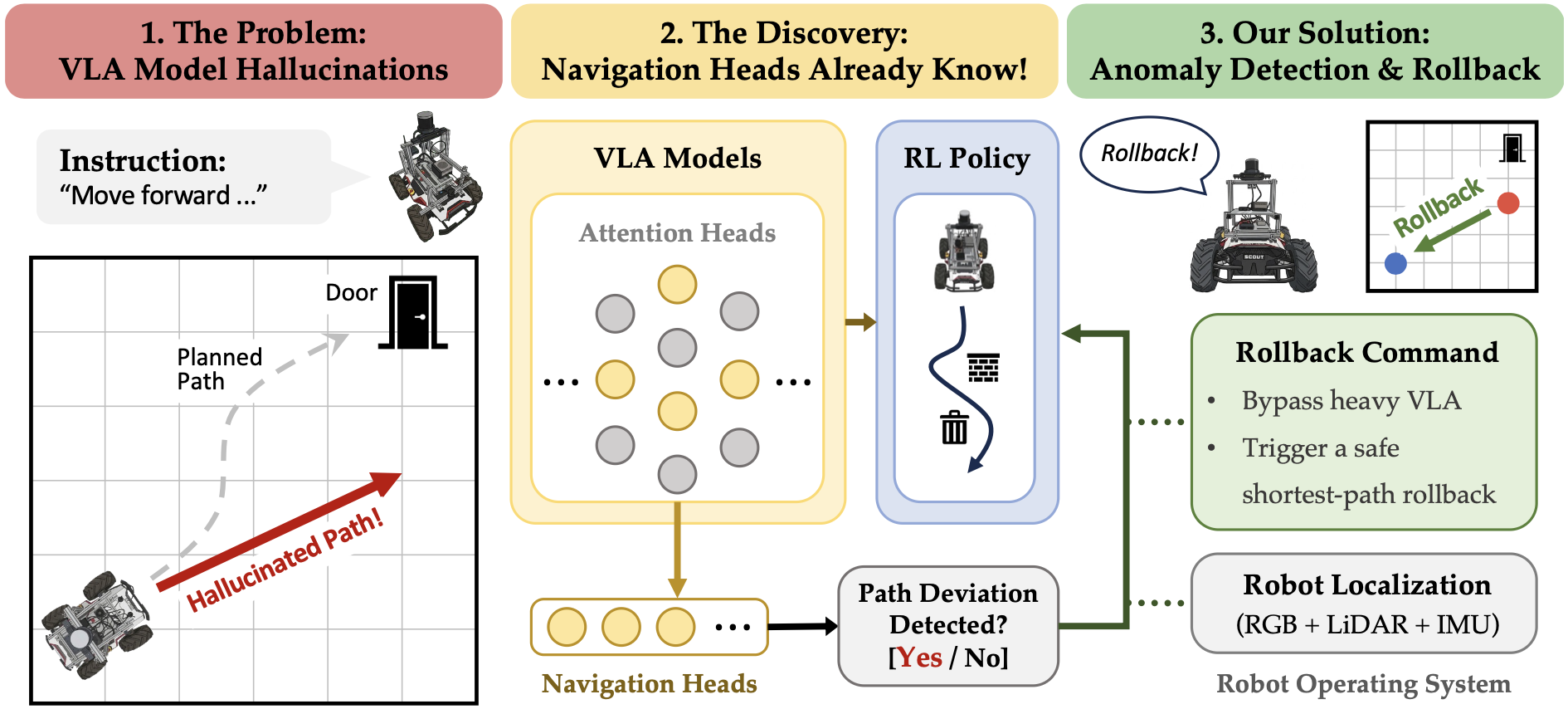
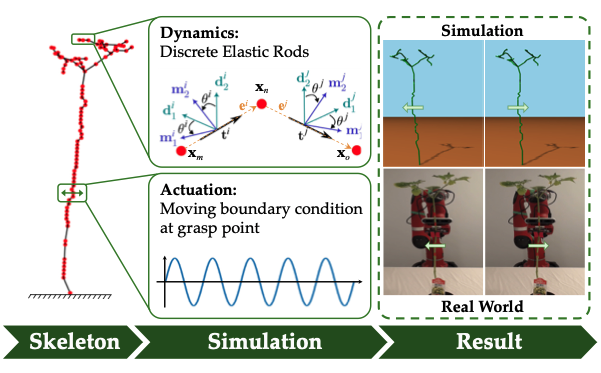
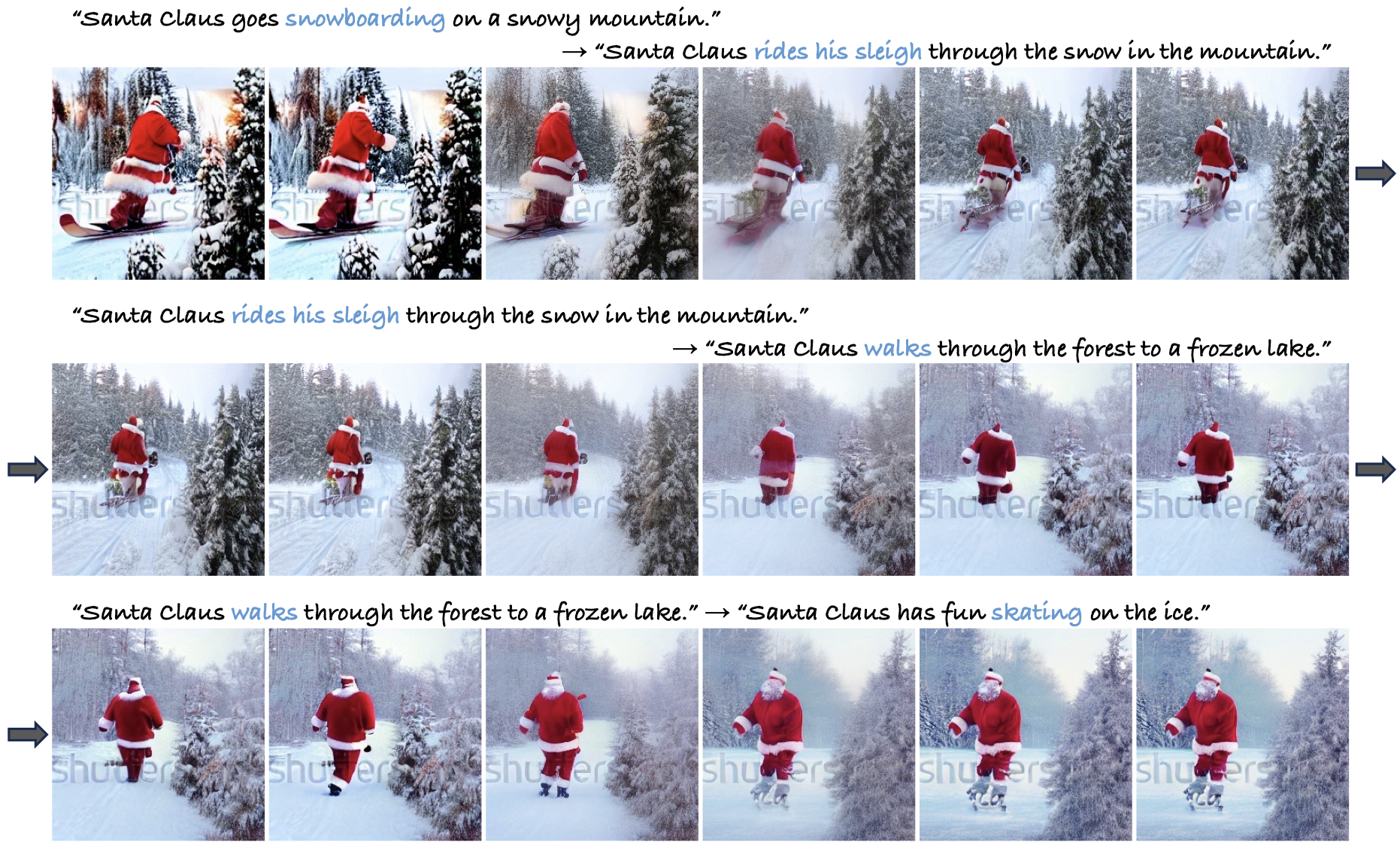
I am a Ph.D. student at Korea University, advised by Prof. Sangpil Kim. My research explores the internal structures of AI models to solve challenges across diverse domains, spanning autonomous systems for vehicles and robotics, multimodal generative models, and AI safety.
Previously, I served as a Visiting Graduate Researcher at University of California, Los Angeles (UCLA), advised by Prof. M. Khalid Jawed. In this role, I led a Smart Farm project team, driving the end-to-end deployment of robotics—specifically UGVs and manipulators—from mechanical machining and sensor fusion to software, AI, and field operations.
Contact
- jhwan@korea.ac.kr
-
Woojung Hall of Informatics, Korea University,
Seoul, Republic of Korea
Positions
-
Mar 2024 – Feb 2029 (exp.)
-
Mar 2025 – Mar 2026