FaceShield: Defending Facial Image against Deepfake Threats
IEEE/CVF International Conference on Computer Vision (ICCV) 2025
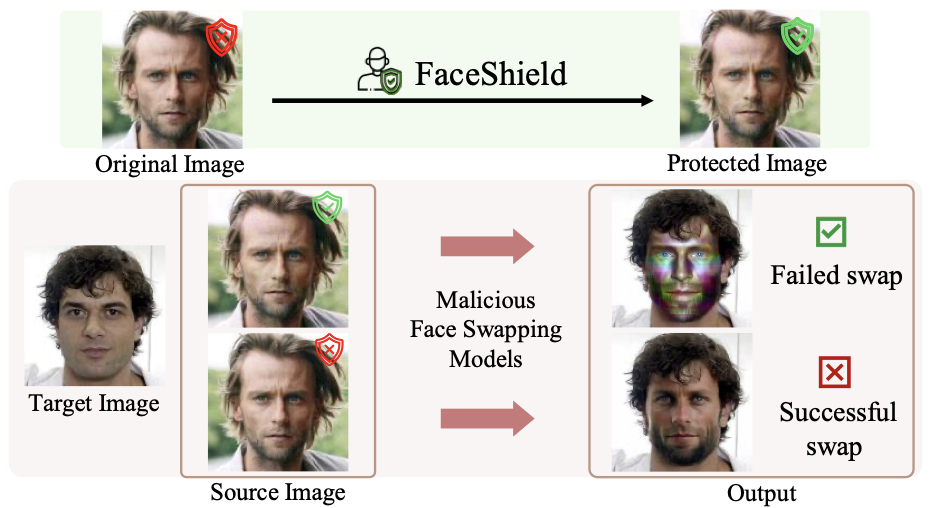
TL;DR
We propose FaceShield, a proactive defense that embeds invisible adversarial noise into facial images to neutralize deepfake face swapping. Prior defenses target only the general noise addition and removal process of diffusion models, whereas FaceShield directly disrupts the cross-attention conditioning mechanism, the core bottleneck through which the original face is projected into the deepfake output. By computing gradients at this exact pathway, the method achieves maximized disruption with only minimal perturbation. Defense coverage is further extended to GAN-based architectures by jointly attacking common facial feature extractors. To prevent the protective noise from being erased by image compression or purification, we apply Low-Pass Filtering (LPF), and to eliminate visually noticeable noise boundaries, we incorporate a Gaussian blur. As a result, FaceShield achieves state-of-the-art protection against the latest DM-based deepfake models, while also exhibiting strong transferability to GAN-based architectures, with lower noise visibility than all baselines.
Key Contributions
- First defense directly targeting the diffusion deepfake core pathway — we disrupt the Key-Value pairs in cross-attention where the source face is synthesized, a mechanism entirely overlooked by prior defenses. Defense coverage is further extended to GAN-based models by targeting facial feature extractors under a single unified perturbation.
- Enhanced imperceptibility via Gaussian blur — by smoothing out harsh differences between adjacent noise pixels, visual artifacts are reduced, making the protective noise far less noticeable to the human eye.
- Robustness against purification via Low-Pass Filtering — by concentrating noise in low-frequency components, the defense remains highly effective even after JPEG compression, bit reduction, and resizing.
Project Design
Motivation: Why Prior Defenses Fail on Deepfakes

(a) Image Editing
Uses a single image as query Q and modifies it via a text prompt. Prior defenses are designed around this pathway.
(b) Deepfake
Uses two images where the target serves as query Q, while the source face enters as Key K and Value V through cross-attention. This is a fundamentally different conditioning pathway that prior defenses entirely overlook.
FaceShield directly disrupts this K-V mechanism, targeting the bottleneck where the source identity is injected into the output.
Overall Architecture
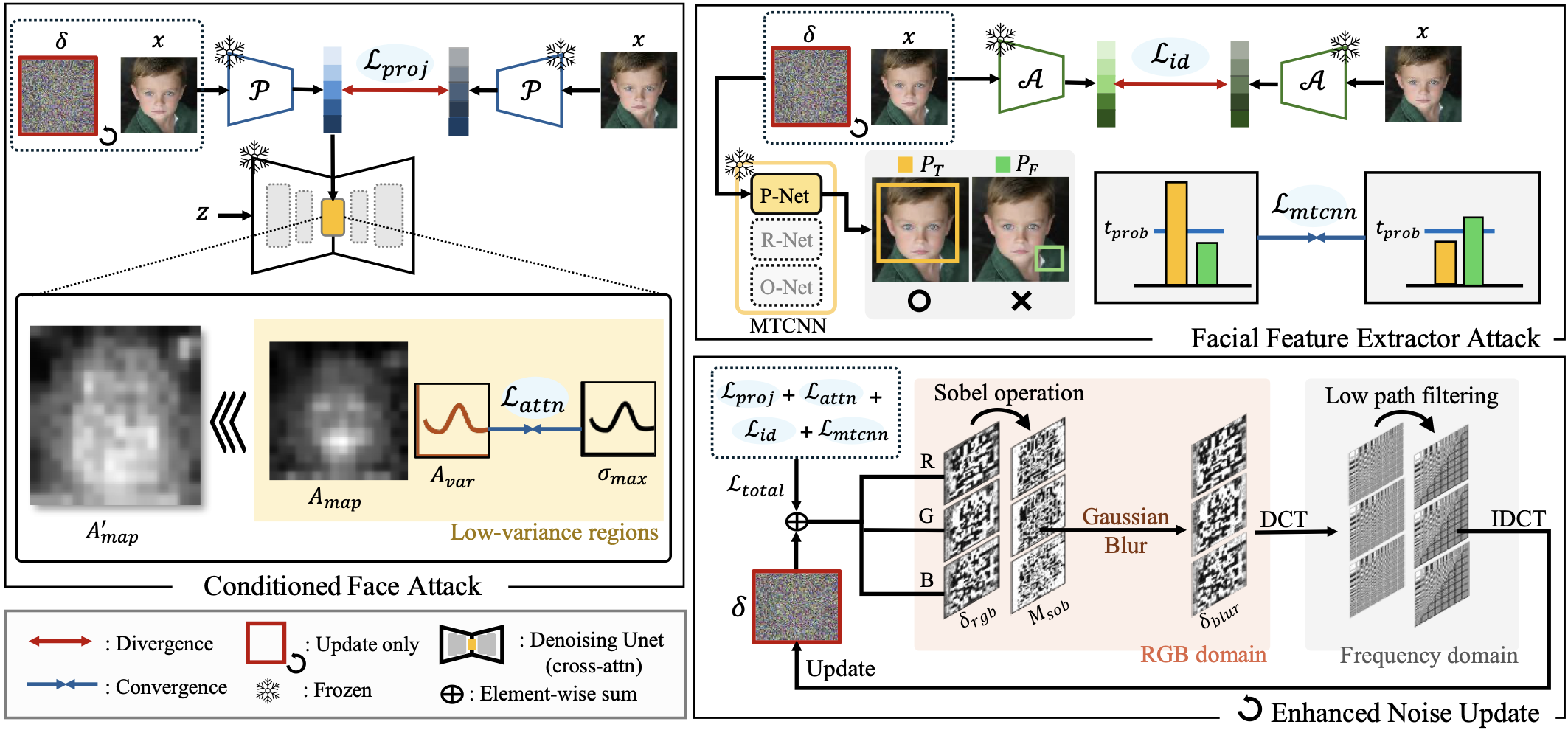
(i) Conditioned Face Attack
When a source face conditions a DM-based deepfake, it is projected through a CLIP Image Projector and injected into the denoising UNet as key K and value V. FaceShield attacks this pathway via two modules: (1) Face Projector Attack — corrupts the source face embedding at the projector output. (2) Attention Disruption Attack — disrupts mid-layer cross-attention to prevent source face features from conditioning the generation.
(ii) Facial Feature Extractor Attack

MTCNN's three-stage cascade (P-Net → R-Net → O-Net) for face detection and landmark localization.
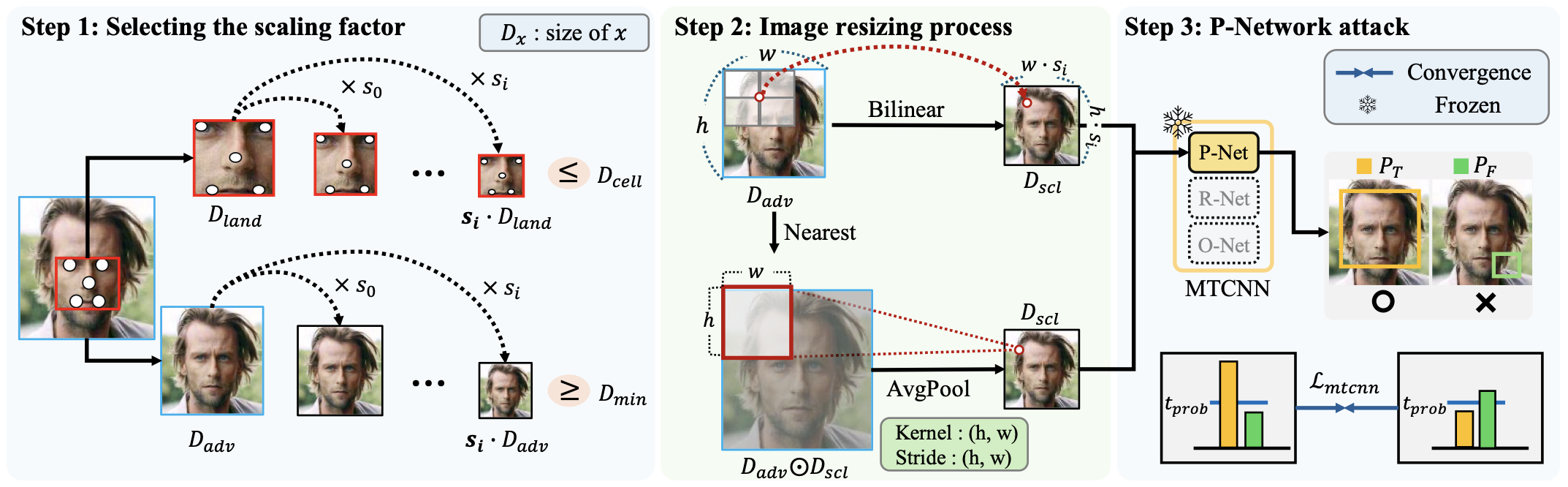
The MTCNN attack adversarially perturbs the P-Net bounding box probabilities across multiple scales, ensuring the noise disrupts face detection regardless of interpolation mode or framework (PyTorch / TensorFlow). By combining this with an ArcFace identity attack, FaceShield performs a joint ensemble attack that broadly covers GAN-based deepfake models under a single perturbation.
(iii) Enhanced Noise Update
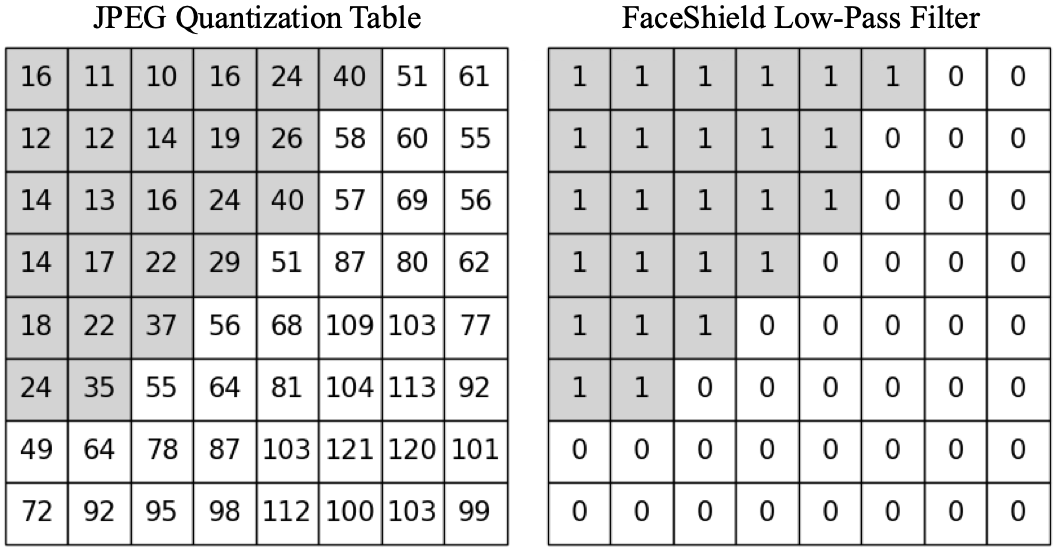
The adversarial noise is transformed to the frequency domain via 8×8 DCT patches. Using the Luminance Quantization Table — the same mask applied during actual JPEG compression — only low-frequency components are retained, then reconstructed via IDCT. This concentrates the perturbation in a band that survives JPEG compression without being discarded.
Even under a bounded noise budget (e.g., δ = 12/255), adjacent pixels can receive opposite extremes (e.g., +12 and −12), creating a local contrast gap of up to 24 that becomes visually conspicuous.

Sobel filtering identifies these boundary regions where neighboring noise values diverge sharply, and Gaussian blur is selectively applied to smooth them out, maximizing imperceptibility without affecting the overall perturbation strength.
Experiments
Protection across Diverse Deepfake Models

FaceShield protects against 6 deepfake models — DiffFace, DiffSwap, FaceSwap, IP-Adapter (DM-based, orange box) and SimSwap, InfoSwap (GAN-based, blue box). DM-based outputs exhibit distorted artifacts and GAN-based outputs generate unrelated identities, both preventing source face reproduction.
| Method | DiffFace | DiffSwap | FaceSwap | IP-Adapter | ||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| L₂ ↑ | ISM ↓ | PSNR ↓ | HE ↑ | L₂ ↑ | ISM ↓ | PSNR ↓ | HE ↑ | L₂ ↑ | ISM ↓ | PSNR ↓ | HE ↑ | L₂ ↑ | ISM ↓ | PSNR ↓ | HE ↑ | |
| CelebA-HQ | ||||||||||||||||
| AdvDM | 0.021 | 0.471 | 39.368 | 4.22 | 0.068 | 0.199 | 28.362 | 4.68 | 0.303 | 0.245 | 21.615 | 4.52 | 0.207 | 0.235 | 25.332 | 2.76 |
| Mist | 0.021 | 0.468 | 39.443 | 3.94 | 0.067 | 0.201 | 28.384 | 4.18 | 0.287 | 0.230 | 22.263 | 4.78 | 0.152 | 0.265 | 28.213 | 4.26 |
| PhotoGuard | 0.022 | 0.469 | 39.194 | 3.82 | 0.068 | 0.201 | 28.292 | 4.58 | 0.282 | 0.238 | 22.316 | 4.44 | 0.153 | 0.268 | 28.101 | 4.44 |
| SDST | 0.021 | 0.470 | 39.512 | 4.08 | 0.067 | 0.207 | 28.383 | 5.04 | 0.274 | 0.261 | 22.582 | 4.68 | 0.147 | 0.273 | 28.440 | 4.32 |
| Ours | 0.044 | 0.243 | 32.052 | 5.76 | 0.072 | 0.163 | 27.833 | 6.20 | 0.336 | 0.194 | 20.759 | 6.16 | 0.350 | 0.072 | 20.266 | 6.60 |
| Ours (Q=75) | 0.043 | 0.259 | 32.259 | — | 0.070 | 0.169 | 28.034 | — | 0.317 | 0.209 | 21.286 | — | 0.326 | 0.112 | 20.867 | — |
| VGGFace2-HQ | ||||||||||||||||
| AdvDM | 0.042 | 0.479 | 33.064 | 3.68 | 0.105 | 0.215 | 24.769 | 4.78 | 0.419 | 0.361 | 18.596 | 4.38 | 0.251 | 0.271 | 23.250 | 2.36 |
| Mist | 0.041 | 0.478 | 33.215 | 4.26 | 0.102 | 0.227 | 24.964 | 3.94 | 0.379 | 0.259 | 19.626 | 4.50 | 0.181 | 0.291 | 26.070 | 4.10 |
| PhotoGuard | 0.043 | 0.479 | 32.938 | 3.96 | 0.110 | 0.215 | 24.272 | 4.18 | 0.373 | 0.266 | 19.655 | 4.14 | 0.180 | 0.294 | 26.157 | 3.82 |
| SDST | 0.041 | 0.483 | 33.242 | 5.30 | 0.107 | 0.225 | 24.506 | 4.58 | 0.359 | 0.258 | 19.996 | 4.14 | 0.166 | 0.292 | 26.784 | 4.06 |
| Ours | 0.062 | 0.278 | 29.204 | 6.10 | 0.113 | 0.177 | 24.054 | 6.12 | 0.453 | 0.237 | 17.919 | 6.16 | 0.382 | 0.112 | 19.478 | 6.42 |
| Ours (Q=75) | 0.060 | 0.308 | 29.435 | — | 0.112 | 0.185 | 24.201 | — | 0.421 | 0.237 | 18.573 | — | 0.377 | 0.167 | 19.618 | — |
Comparison of perturbation effectiveness among baseline methods on four deepfake models using the CelebA-HQ and VGGFace2-HQ datasets. Bold = best, underline = second best per column.
Comparison with State-of-the-Art Baselines

Compared to AdvDM, Mist, PhotoGuard, and SDST on IP-Adapter deepfakes, prior methods fail to disrupt the output. FaceShield causes visible generation failures, confirming that attacking the conditioning pathway is essential for DM-based deepfake protection.
Targeting the mid-layers of the denoising UNet produces the strongest protection compared to using only down/up layers or all layers, as confirmed by our ablation study. Mid-layer cross-attention carries the highest sensitivity to the conditioning source face, as this is where source identity is most strongly encoded and the face-swap signal is concentrated, making it the most effective and precise attack target.

Face Detection Disruption — MTCNN

Under FaceShield's perturbation, MTCNN fails to produce high-confidence bounding boxes at the P-Net stage (bottom row), preventing detected face crops from propagating to downstream deepfake models — compared to the unprotected case where detection succeeds cleanly (top row).
Robustness to Image Purification
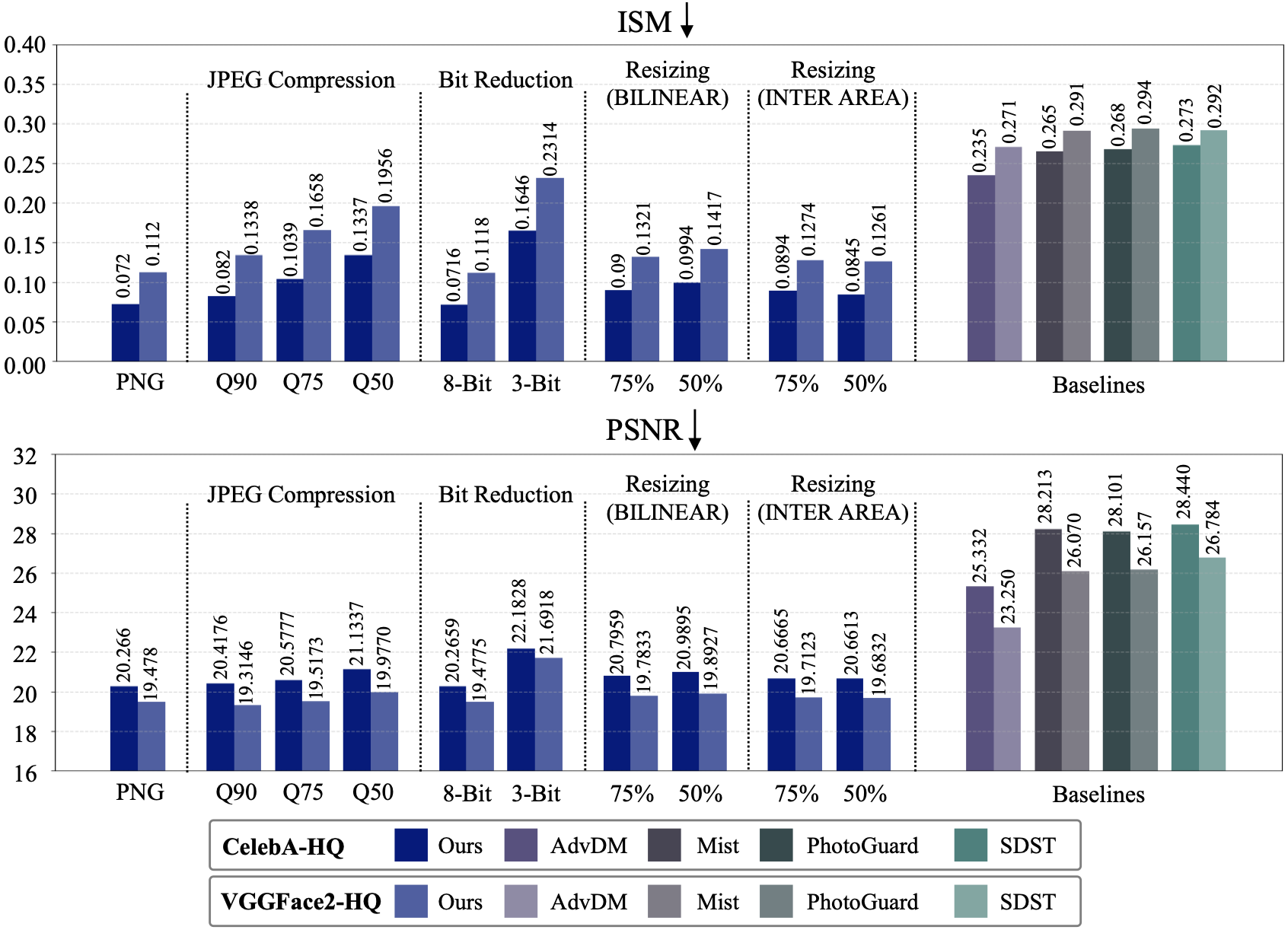
FaceShield's low-frequency noise concentration keeps performance close to lossless (PNG) across JPEG compression (Q90/75/50), bit reduction (8-bit/3-bit), and resizing (75%/50%, BILINEAR/INTER AREA) — consistently outperforming all baselines on both ISM and PSNR metrics.

Qualitative results after JPEG compression (Q90, Q75, Q50) and bit reduction (8-bit, 3-bit). Protection degrades minimally relative to the lossless PNG baseline.

Qualitative results after 75% and 50% resizing (BILINEAR and INTER AREA). The perturbation remains effective across both interpolation modes.
| Method | CelebA-HQ | VGGFace2-HQ | ||||||||
|---|---|---|---|---|---|---|---|---|---|---|
| LPIPS ↓ | PSNR ↑ | SSIM ↑ | FR ↑ | HE ↑ | LPIPS ↓ | PSNR ↑ | SSIM ↑ | FR ↑ | HE ↑ | |
| AdvDM | 0.4214 | 30.4476 | 0.8438 | 2.1077 | 3.86 | 0.4108 | 30.2523 | 0.8436 | 2.0667 | 3.66 |
| Mist | 0.5492 | 29.9935 | 0.8684 | 1.6583 | 4.70 | 0.5208 | 29.9068 | 0.8721 | 1.6872 | 4.34 |
| PhotoGuard | 0.5515 | 29.9127 | 0.8669 | 1.6538 | 4.82 | 0.5221 | 29.8204 | 0.8712 | 1.6824 | 4.62 |
| SDST | 0.5409 | 31.4762 | 0.9033 | 1.6767 | 5.12 | 0.5060 | 31.3545 | 0.9092 | 1.6892 | 4.48 |
| Ours | 0.2017 | 32.6289 | 0.9394 | 18.4651 | 5.64 | 0.1941 | 31.5799 | 0.9341 | 18.0400 | 5.28 |
Noise quality comparison under identical settings. Our method shows the lowest distortion (LPIPS, SSIM, PSNR) and highest low-frequency energy (FR). Bold = best, underline = second best per column.
Resource Cost Comparison
| Method | ISM ↓ | LPIPS ↓ | VRAM | Sec. ↓ |
|---|---|---|---|---|
| AdvDM | 0.288 | 0.4214 | 20 GB | 39 |
| Mist | 0.291 | 0.5492 | 22 GB | 80 |
| PhotoGuard | 0.294 | 0.5515 | 28 GB | 234 |
| SDST | 0.303 | 0.5409 | 11 GB | 34 |
| Ours | 0.168 | 0.2017 | 15 GB | 24 |
Resource cost comparison with baseline methods. Bold = best, underline = second best per column.
Transferability across IP-Adapter Variants
FaceShield generalizes across eight IP-Adapter variants (ControlNet, ImageVariation, Multi-modal prompts, Plus/PlusXL, FaceID, FaceIDPlus) — demonstrating robust transferability not only across structurally different architectures but also across models sharing the same backbone with different pre-trained weights.
Conclusion
We propose FaceShield, a proactive invisible protection technique against diverse deepfake systems. By targeting the cross-attention conditioning pathway specific to DM-based deepfakes — a mechanism overlooked by prior defenses — and jointly disrupting common facial feature extractors used by GAN-based models, FaceShield achieves broad architectural coverage under a single perturbation. An enhanced noise update combining Gaussian blur and low-pass filtering further ensures that protection is both imperceptible and robust to JPEG compression and resizing purification. Extensive experiments confirm state-of-the-art protection with the lowest noise visibility among all baselines, while requiring significantly less computation time and memory.
Acknowledgement
Research collaboration with Samsung Research (Jaewook Chung), contributing to the development of proactive deepfake defense technology.
This work was supported by the Korea Creative Content Agency (KOCCA) under Grant RS-2024-00345025 and RS-2024-00348469, the National Research Foundation of Korea (NRF) funded by MSIT (RS-2025-00521602), and the Institute of Information & Communications Technology Planning & Evaluation (IITP) funded by the Korean government (MSIT) under Grant No. RS-2019-II190079 and IITP-2025-RS-2024-00436857.